Most Popular
Start Routing Notifications Today!
Courier is a notification service that centralizes all of your templates and messaging channels in one place which increases visibility and reduces engineering time.
Sign-up

From MVP to Production Ready With Serverless
Having been at startups my entire career, I’ve encountered the dichotomy between speed and scale when building software products. The usual attitude entrepreneurs take when building the first iterations of their products is “...we aren’t anywhere close to facing problems of scale, so let’s worry about that when we get there.” This first version of the software is built and shipped fast, and it’s only a matter of time before engineers realize that they simply don’t have the foundation to iterate quickly. Inevitably, limitations within their own infrastructure cause slow development cycles, impossible deadlines, and too much stress to maintain creativity and functionality. Trust me, I have been there.
In a startup, it is difficult, if not impossible, to find the resources necessary to solve these problems at scale. I have found that Serverless is an excellent response to this challenge. I think Jeremy Daly has summarized it nicely.
“Serverless gives us the power to focus on delivering value to our customers without worrying about the maintenance and operations of the underlying compute resources.”**
In this post, I want to explore some of our favorite Serverless stories from Courier, review some Serverless basics, and explore how Serverless has empowered our team to accomplish more with less. Perhaps through these musings, you can gain a better understanding of the Serverless landscape and determine if it's the right approach for your next project or startup.
60 Days to Monetization
When I joined Courier, I was intrigued about why founder Troy Goode decided to go with Serverless, since it was a relatively new technology, with a small community of active developers. Upon asking, he said he was looking for “the speed of Ruby on Rails or Django with the scale of Kubernetes” without having to choose one over the other. Serverless framework was a perfect fit. Troy, as a team of one, was able to build Courier’s powerful send pipeline, pitch potential customers, and actually land a paying account within 60 days of development. This was incredibly exciting for me and validated the idea that a small team can become production-ready extremely quickly.
What’s even more impressive is that the core design of our send pipeline has remained largely unchanged in the last 18 months. This has allowed us to focus on specific customer use cases and not the underlying infrastructure. This foundation has served us well, allowing us to continue to develop at a rapid pace and respond to customer feedback.
S3 is Our Friend
At Courier, we are big fans of S3. With all the new features and services that seem to explode out of reInvent each year, S3 doesn’t get the love it deserves. From its guaranteed uptime of 99.9%, its dead-simple API, and low cost, what’s not to love!
One of my favorite design patterns that I picked up at Courier is the Web Service to S3 pattern due to its flexibility and simplicity.
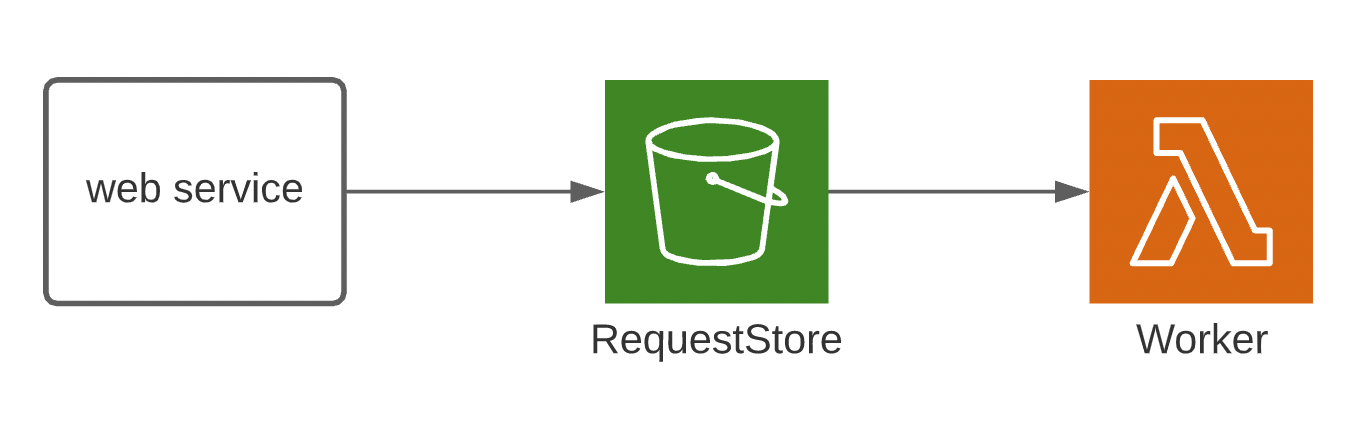
This pattern is an excellent fit for when you need to manage time-consuming processing but don’t want to wait for its completion. In this example, a Web Service puts an HTTP request onto an S3 bucket called RequestStore. This will trigger a Lambda function called Worker, which can then send the request to another service to be processed.
This is particularly easy to configure with Serverless framework. First, you need to define an S3 bucket using cloud formation(In a production environment you need to apply a stricter policy to your S3 bucket. I added a basic PublicRead here for brevity.):
1resources:2Resources:3RequestStore:4Type: AWS::S3::Bucket5Properties:6AccessControl: PublicRead
Then define the lambda function with an S3 trigger event:
1Worker:2events:3- s3:4bucket:5Ref: RequestStore6event: s3:ObjectCreated:Put7handler: handlers/worker.default
I love being able to reference this manifest later and visualize the system just by looking at the code.
Another powerful use case for S3 is avoiding the 400KB item limit with DynamoDB. When you need to store large item attributes in Dynamo, you can store them as an object in Amazon S3 and then store the object reference in the Dynamo item.
This approach has proven useful on numerous occasions at Courier, but is not without its tradeoffs. This strategy does not support transactions, therefore your application should handle any failures or errors that may occur.
Lambda Bottlenecks From A Dynamo Stream
An interesting aspect of Serverless development is the ability to finely tune your services based on their usage. At Courier, this was done out of necessity after we noticed a performance issue in one of our key logging services. Here is a simplified drawing of the problematic design.
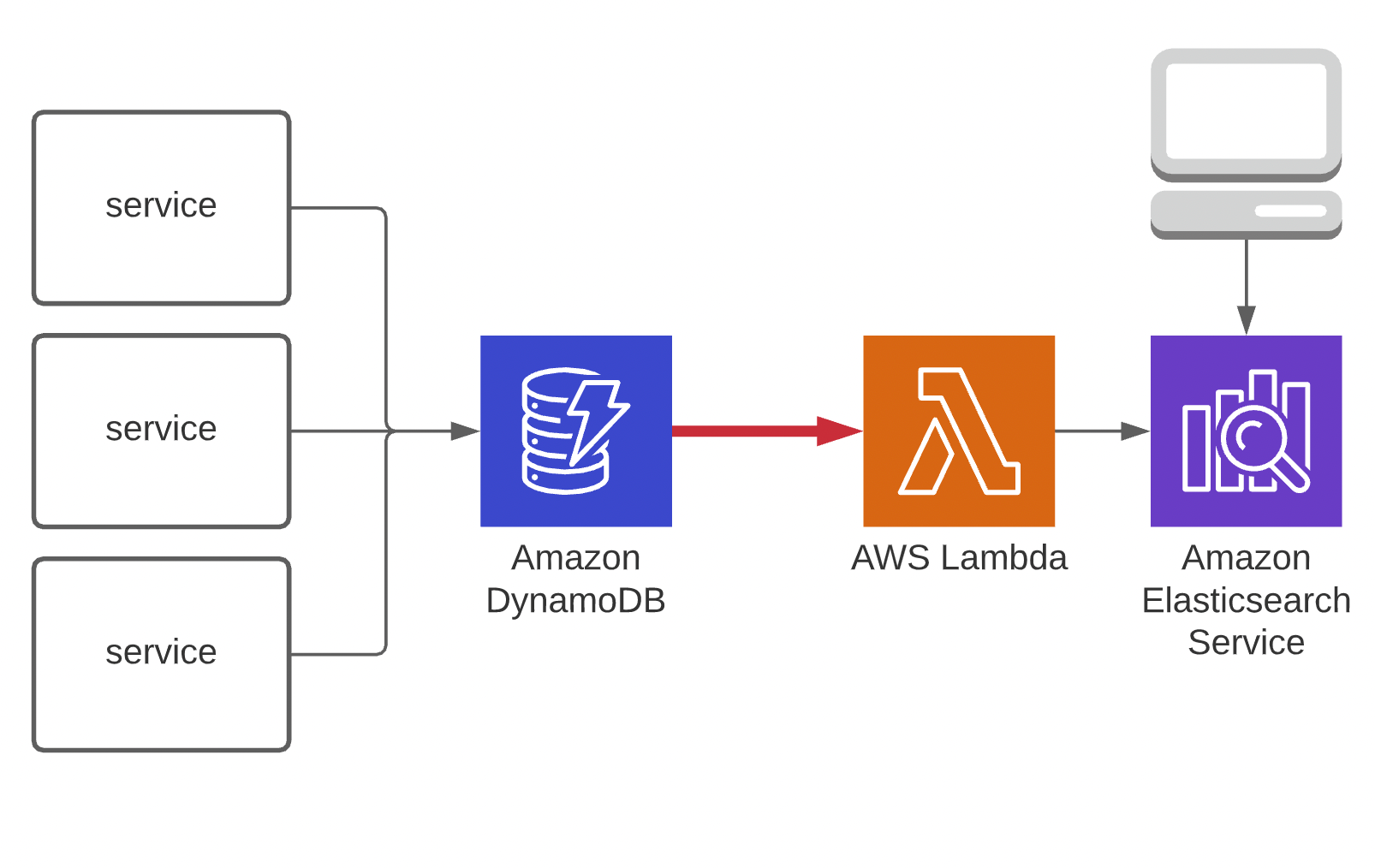
In this scenario, we have several services that write to a Dynamo table. This table streams batches of records to a lambda function, which writes these records to Elastic to be queried by a UI. After further investigation, we found that the lambda’s iterator age was continuously increasing, causing a performance issue in the UI.
Let’s quickly define some terms before we jump to the happy ending of this story. A lambdas batchSize is simply the number of records to read from the event streams shard. A lambda’s iterator age is a CloudWatch metric that measures how long it took to process the last record in the batch. Since our lambda was processing new events and the iterator age was increasing, this meant that it was taking more time to process each new record due to backpressure. In other words, as more records were being written to the table, it was taking these records longer to reach the UI.
The cause was due to an increase in the product's usage, so this turned out to be both a great problem to have and one with a relatively simple solution. Depending on the Lambda’s event source, AWS allows you to define the batch size of records for the triggering lambda event. In addition to batch size, you can also define the parallelizationFactor, which provides a multiple of concurrent lambda invocations per shard. For example, if Parallelization Factor is set to 2, you can have 200 concurrent Lambda invocations to process 100 shards. Thanks to Serverless Framework, this is as simple as defining the two parameters within the event section of the lambda definition.
1LambdaWorker:2events:3- stream:4type: dynamodb5arn:6Fn::GetAtt:7- DynamoTable8- StreamArn9batchSize: 110parallelizationFactor: 511handler: handlers/lambda.worker
AWS and Serverless made this situation a whole lot easier to deal with thanks to the built-in CloudWatch metrics and the configurability of AWS services. After reconfiguring the lambda, we saw almost immediate back pressure relief and went about our day.
Green Field: Automations
Starting a new project from scratch is exciting. Optimism is high, there are lots of creative discussions and opportunities to innovate. When I joined Courier, I was fortunate enough to lead the effort, alongside CTO Seth Carney, on a new greenfield project called Automations, which set out to allow users more control of how and when they could send messages.
We set out to allow users to define an Automation from a discrete set of job definitions, that we later named steps. To process these steps we designed a simple but effective job processing system.
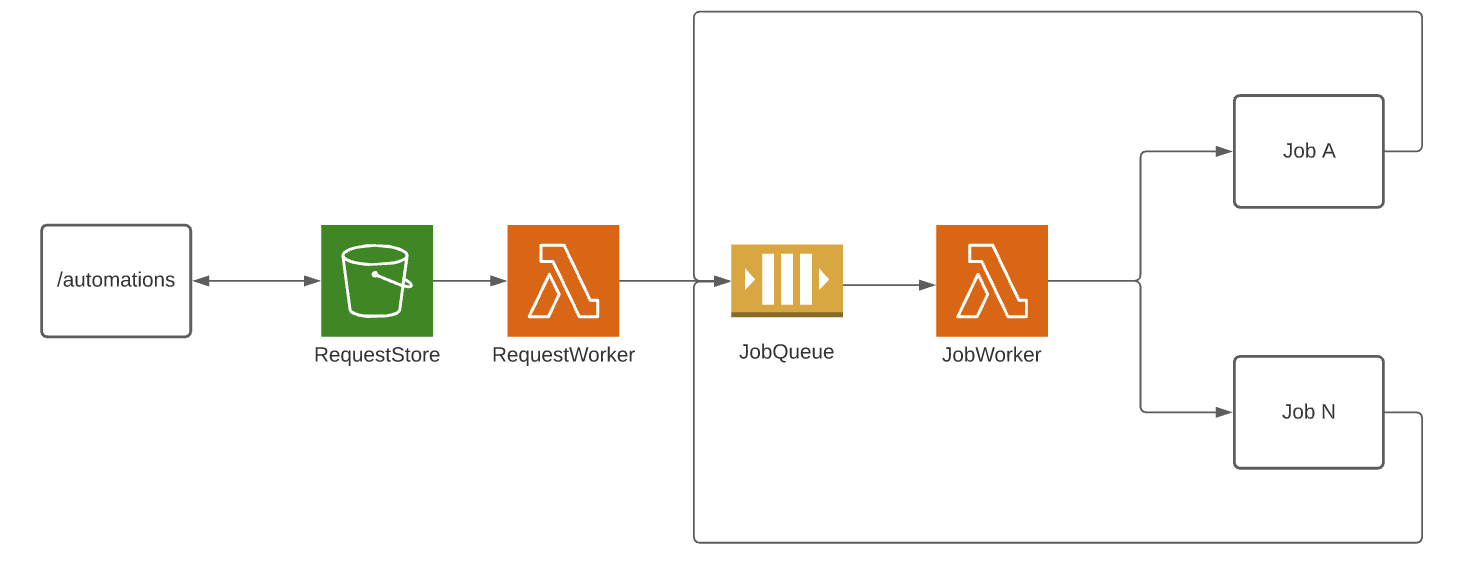
First we used the trusty Web Service to S3 design pattern I talked about earlier to quickly validate the incoming automation definition, store it into S3, and return a response to the user. At this point no jobs have been processed, only validated. We don’t want the user to wait for the entire automation to execute before receiving a response.
Next, the request is picked up by the RequestWorker, where each individual job is processed in the order in which it was defined. After experimenting with other services, we chose SQS as a job processor, due to its unlimited throughput and its ability to retry messages with a DLQ. Finally, the JobWorker is triggered with the job definition in the event payload. Its role is to execute the job based on its definition, then enqueue the next job. Defining an SQS Queue and a Lambda with an SQS trigger is similar to the Web Service to S3 pattern we defined earlier.
First let’s define the Queue with CloudFormation:
1resources:2Resources:3JobQueue:4Type: AWS::SQS::Queue5Properties:6VisibilityTimeout: 60
Then define the lambda function, this time with an SQS trigger event:
1JobWorker:2events:3- sqs:4arn:5Fn::GetAtt:6- JobQueue7- Arn8handler: handlers/worker.default
Notice the funny-looking syntax. This is called a cloud formation intrinsic function, which is a way to retrieve the underlying ID of the AWS resource. You will notice that this was not required for our S3 trigger example, which is kind of a quirk of CloudFormation. Since it is difficult to keep track of what services require which intrinsic functions, I found this amazing cheatsheet from Yan Cui very helpful.
We were able to design, implement, and ship this architecture within a week. Considering this was implemented with a team of one, I am very proud of that accomplishment. Since then, we have added many more services, features, and functionalities to Automations, but this first implementation not only kicked off a great working relationship with my colleagues, but it also proved to me the true value of a Serverless driven infrastructure.
Serverless does not come without its own set of challenges and frustrations. Regardless, Serverless has become my favorite way to build products and companies. When faced with the uncertainty of the market and the need to iterate quickly I think choosing Serverless allows tremendous development speed with scale built in. What are your thoughts on Serverless? I hope you enjoyed these Serverless stories and I hope you feel empowered to dive in and build your next project with Serverless.
Start Routing Notifications Today!
Courier is a notification service that centralizes all of your templates and messaging channels in one place which increases visibility and reduces engineering time.
Sign-up
More from Notifications Landscape

The Product Manager's Guide To Building Notification Systems: Decoupling Templates From Code
This is part 2 of a 5 part series. In this article, we explain how decoupling notifications from your application’s codebase can help make notification projects less complex and less risky for product teams.
Anwesa Chatterjee
September 23, 2022

The Sub-prime Crisis of Notifications
There is a direct connection between all the unnecessary notifications you get on your phone and the sub-prime financial crisis of 2008: lack of accountability for bad behavior.
Nočnica Mellifera
September 14, 2022
Free Tools
Comparison Guides
Build your first notification in minutes
Send up to 10,000 notifications every month, for free.
Get started for free
Build your first notification in minutes
Send up to 10,000 notifications every month, for free.
Get started for free
© 2024 Courier. All rights reserved.