Most Popular
Start Routing Notifications Today!
Courier is a notification service that centralizes all of your templates and messaging channels in one place which increases visibility and reduces engineering time.
Sign-up
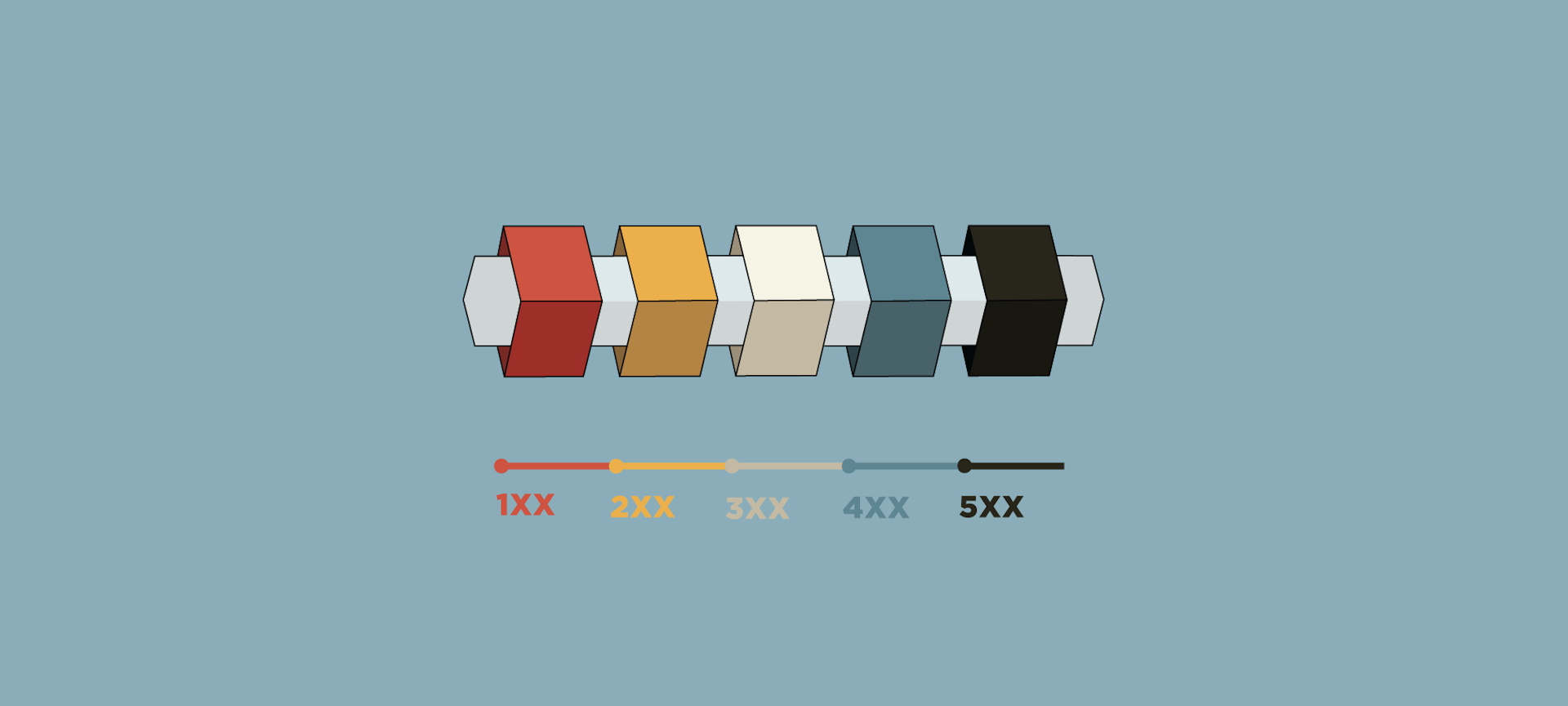
What to consider when standardizing your REST APIs
Recently, we’ve been working on standardizing some aspects of Courier’s REST APIs, such as naming conventions and HTTP status response codes. While Courier has an extensive web UI where our Design Studio lives, we have multiple APIs behind the scenes that do a lot of the heavy lifting. It’s important to make sure these APIs are as developer-friendly as possible, meaning they should be semantically consistent and predictable. I thought I’d share some of our guiding principles and learnings that might be useful for your team as well.
Standardization helps your users avoid bugs and code debt
As with most things in life, when it comes to writing a REST API, consistency is key. A REST API is a communication layer, and like any language, it has certain rules and conventions that should be followed in order for things to run smoothly. The different methods (GET, POST, DELETE, etc.) have specific behaviors that users will expect the API to follow. HTTP response codes are standardized as well so that users know what the problem was and can take some action depending on the response.
Deviations from the norm or inconsistencies within the API itself means there most likely will be differences between what the user expects to happen, and what the API’s actual behavior looks like. As a developer, you’ve probably experienced this (we definitely have), where the way that you call one part of the API looks completely different from the way you make a nearly identical call in another part of the API. In the worst case, this means your users end up with buggy code, and in the best case, it means they are going to have to branch their code to handle any special cases, making it harder for them to maintain the integration. Plus, any nonstandard aspects of your API will also make it harder for your own team to manage and update it.
What elements should you standardize?
- Your HTTP methods. While there might be different philosophies here, we recommend using the most specific method that fits. For example, using a generic POST for updating resources doesn’t tell the user anything about the update behavior. Instead, you might want to support PUT and PATCH methods where appropriate, so that users have more information about the type of update they’re making. A PUT completely overwrites the resource if it already exists, while a PATCH is meant for a partial update.
- Your variable names. We’ve recently updated our variable names on our inbound requests so that everything is “snake case” (meaning words are separated by an underscore , like first_name) rather than camel case (firstName). This is important because case-sensitivity and URLs don’t generally play well together!
- Your responses. We’ll talk later about why it’s important to return objects in your responses in order to future-proof your API.
- Your HTTP response status codes. This tells your user what happened as a result of their API call, so it’s important that these codes are used consistently. We’ll go through these in more detail in a moment.
- Your error reporting. It’s useful to create a standard interface for reporting errors that users can always expect from your API, and this helps you extend your API as well if you need to add more types of errors.
Standardizing your HTTP response status codes
When an API call is made, the server returns a three-digit HTTP status code in its response. These codes start in the 100s and go to the 500s. A lot of the work we’ve done recently has been to standardize these responses so that they fully describe Courier’s behavior in every case.
Success conditions
Codes in the 200s indicate that the client’s request was successful. Within this category, there are several possible statuses. The ones we care about at Courier are 200, 202 and 204.
A 200 response code means that you were successful, *and *you can expect more information in the response body (such as the data that you requested with a GET). To create a more developer-friendly API, we’ve been moving some of these generic 200 responses to more specific 202 or 204 responses. A 202 means that Courier has accepted the request, but hasn’t been able to process it yet. This is mostly used for our Send pipelines and tracking. And a 204 means that the request was successful, but there’s no data to return back in the body. This might happen for example if you DELETE a resource; beyond acknowledging that this was successful, there’s nothing else that the user expects to receive in that moment from Courier.
A note about status code 201: officially this code means that a resource was created, but we’ve found that in practice most APIs just return a 200 for this, since the fact that you’re using the API with an action like POST means that your intention is to create a resource.
Error conditions
As we get into error conditions, response codes become even more useful. 4xx codes describe various types of client errors that can happen (for Courier, usually this is a data validation error), while 5xx codes are for server-side errors (something happened with Courier’s backend that caused the request to fail).
One thing we’ve found useful is to develop a consistent and standard error interface, so that when you’re integrating with Courier, you can always expect that same structure for an error response. This looks like:
1{2code?: string; // a string indicating the error code3doc_url?: string; // an optional link to documentation4message?: string; // a human-readable error message5type: // the type of error returned6| “api_error”7| “authentication_error”8| “authorization_error”9| …10}
By defining an opinionated error response type it allows Courier to convey further information to the developer which could be used to fix and resubmit the request.
Other ways to make your REST API more developer-friendly
Use Nesting
If you want to make your API easier to expand in the future, it’s important to accept and return objects that encapsulate the raw data. Even if you’re just returning something like a message ID, returning an object will help you make sure that additions to the response later on don’t break anything for your legacy users.
For example, instead of returning a message tracking ID like this:
“4bccd5bf-3bdc-49f4-b2d7-7851338bd105”
With objects at the root level, your API would look more like this:
1{2messageId “4bccd5bf-3bdc-49f4-b2d7-7851338bd105”3}
Make your API idempotent
When you API is idempotent, this means that retries won’t affect the results in unexpected ways. For example, if you request to send an email through an API, and don’t receive a response for some reason (a network error, for example), you might not know what to do. Should you resend the request and risk sending duplicate emails? If the API is idempotent, you don’t have to worry, because a retry will not result in duplication.
At Courier, we support idempotency on send requests through an Idempotency-Key header, which signals to Courier that multiples of the same request should be treated as idempotent
I hope this article has been helpful. We’re currently hiring for engineers. Check out our open roles!
Start Routing Notifications Today!
Courier is a notification service that centralizes all of your templates and messaging channels in one place which increases visibility and reduces engineering time.
Sign-up
More from Engineering

Simplifying notifications with the Courier iOS SDK
Push notifications are a valuable tool for keeping users informed and increasing their engagement with your app. You can use push notifications to alert users about promotions, new content, or any other important updates. While push notifications are a powerful tool, setting up push notifications in iOS can be a daunting task that requires a significant amount of effort and time. Fortunately, the Courier iOS Mobile Notifications Software Development Kit (SDK) simplifies this process.
Mike Miller
March 23, 2023

Building Android push notifications with Firebase and Courier’s SDK
Push notifications have become an essential part of modern mobile apps, allowing you to keep your users engaged and informed. However, implementing push for different platforms can be a complex and time-consuming task, requiring developers to set up and handle token management, testing, and other logistical details.
Mike Miller
March 21, 2023
Free Tools
Comparison Guides
Build your first notification in minutes
Send up to 10,000 notifications every month, for free.
Get started for free
Build your first notification in minutes
Send up to 10,000 notifications every month, for free.
Get started for free
© 2024 Courier. All rights reserved.