Most Popular
Start Routing Notifications Today!
Courier is a notification service that centralizes all of your templates and messaging channels in one place which increases visibility and reduces engineering time.
Sign-up

Tools and Techniques to Establish Your Data Team Early
You can’t really invest in a data team too early. That’s something we learned as a small but growing team. We invested in a data team at an early stage, so we could establish product usage trends, create business insights, and identify areas to improve our product.
If you’re an early-stage startup, start building your data strategy team and architecture as soon as you can. You don’t have to go big—a one-person data team can make a massive difference to your success as you grow.
Hire a Generalist First
When it comes to launching your data team, you might be tempted to hire an expert from the largest brand name you possibly can. Our advice: find someone with early-stage startup experience and has worked with data at scale too.
There are wonderful people with brilliant minds working on large enterprise data teams, but these large teams often have their employees specialize in specific parts of their data platform. That makes sense when you have 10 data engineers on a team or when you have a large team of machine learning data scientists working on pricing algorithms. But when you’ve only got one data role for the entire organization, you need someone who can do a little bit of everything.
It’s important to first hire an all-rounder who can create data insights, develop business hypotheses, and create a scalable data architecture from scratch. You need someone ready to start building the data team from the ground up, preferably someone who can hire out the rest of your team once you’re ready to do so.
This first hire should be someone who has experience building (or at least working on) a data team at an early-stage startup. They need to be able to generate value quickly and have the business acumen to ask the right questions. They should be able to approach data in an 80/20 manner to deliver immediate results instead of diving into the hardest problems that you have.
For the data engineering side, it’s common to hire a consultant or contractor to help set up your architecture. We decided to complement our first hire with a consultant. This way, we have the best of both worlds – an expert in data engineering part time, and a generalist who can maintain data architecture on a day to day basis. We set up strong foundations and also kept our knowledge in house.
A Small Data Team Can Answer Big Questions
Even if you can’t hire right away for all the roles you want on your data team long term, you can do a lot with only one or two of the right people. The key is thinking in terms of scalability and efficiency. What helps your data team do more with less? And how will this work when your team is bigger?
Scalable analyses are extremely important with a small data team. By thinking ahead about how your processes and workflows will function as your team grows, you’ll save time and create valuable solutions for some of your employees’ most time-consuming issues.
For example, we immediately realized that our sales team had no visibility into prospective customer product usage, and it was going to come up often. So we built our sales reps a workspace dash so they can pull the data themselves. Our data team’s job is to enable data-driven decision-making. When we saw an opportunity for a one-time data investment that could lead to hundreds of saved hours on the sales side, we acted on it.
A small data team should also be focused on preventing issues in the future. If you only have the headcount for a one-person data team at the moment, keep them focused on your biggest problems but also budget time to maintain and scale your data architecture to reduce tech debt.
The Tools Our Data Team Uses
From the beginning, our goal was to be forward-thinking with every decision.
Like all startups, we wanted to generate immediate ROI. We use a centralized data warehouse that is our single source of truth – nothing hurts data teams more than having fragmented or untrustworthy data. We’re able to consolidate our data thanks to automations and integrations. This helps us provide valuable insights to the entire company with low lift.
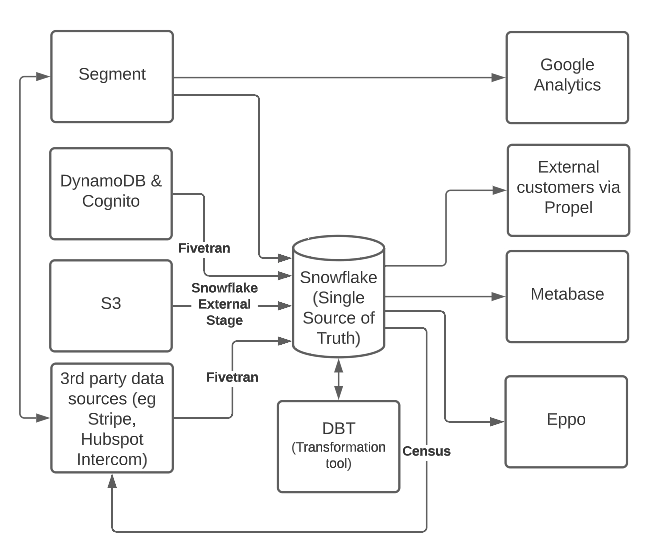
We pipe in all of our data using ELT tools like Segment (which is also our data collection tool), Fivetran, and Snowflake external stages.
Snowflake is the brains of the operation, all of our data gets piped there and we use that as our Single Source of Truth. Establishing this single source of truth is critical for ensuring that all of our metrics are the same across all systems. This helps build trust across our stakeholders and makes it easy for us to join data from multiple sources. For example, while feature usage is helpful for us to look at in isolation, combining this with payment data will create insights on what customers are willing to pay for.
We use dbt to clean all of our raw data into a more usable format. For example, our dim_user table has ~20 tables powering it under the hood, that have a lot of critical info on our customers, such as how many notifications they send and what plan type they are on. By making this so readily available, our non-technical users can quickly draw business insights. We can quickly look at non-paying or self-serve customers that are sending a lot of notifications to identify business contract prospects. Our customer success team also built reports to look at the health of our business contract customers. We also use dbt to clean our data of sensitive information.
We use Census to send our warehouse data back to places such as HubSpot and Courier. This allows our sales and marketing teams to access this information on the platform that they are using on a daily basis.
Metabase is our BI tool. It allows us to create dashboards, write SQL queries, and provide a self-serve format for non-technical users. We’ve found that creating these kinds of self-serve data dashboards allows users to answer a lot of their own questions. They are quick to spin up without large investments upfront like teams that use Looker or Tableau.
For example, we have a KPI dash that shows the top metrics across the company. We can also track how individual workspaces are performing and identify workspaces that we can target for our sales team. We have also brought data-driven decision-making to our product development by deep-diving into our customers’ product usage. One example is that we found that a lot of our users were creating their own Courier instance instead of joining their colleague’s existing Courier instance. Using this insight, our product team went back to the drawing board to create a page that surfaces Courier workspaces that are created by the same business email domain so you can easily request access.
We also use Propel to power our in-app analytics to provide visibility for our end users. One way that we use Propel is to deliver template analytics for our Business-tier customers. Propel allows our engineers to easily put GraphQL visualizations on top of our metrics from our warehouse.
Eppo is our experimentation analytics platform. The way that they define experiments and relevant metrics makes it really easy to scale experimentation without much overhead – it can take as few as five minutes to setup an additional experiment. Having an integration with our warehouse is key – no longer is experimentation a blackbox, and we get to have our internal data layer for free for us to do deep dives. No longer do you need to go to your data team to ask for specific cuts such as “How is this feature affecting paid vs free users?” or “Do we see differences in the US vs Rest of World?” as you get this out of the box with a few clicks. This unlocks more time for our data team and creates a better experience for our Product, Engineering and Design stakeholders.
Our Data Team Is Evolving Again
Now, we’re entering a period of growth, so naturally, we’re evolving our data approach again. Our current goal is to enable our data scientists to build subject matter expertise while still maintaining centralized data standards.
Our current structure is centralized, with a senior analytics engineer reporting to the head of data. It works now since we’re still in the earlier stages of building out a data team. But when the team expands, we will be transitioning to a hybrid model.
Data scientists will cover certain business areas (like the product team), but they’ll still report to the Head of Data. This will allow the data scientists to build subject matter expertise while still maintaining centralized data standards as we continue to grow. Because the data team will always be changing and growing along with the rest of the organization, you need standards that will scale with the business.
If you’d like to learn more about how we approach data standardization, check out our blog post on how Courier became HIPAA compliant.
Start Routing Notifications Today!
Courier is a notification service that centralizes all of your templates and messaging channels in one place which increases visibility and reduces engineering time.
Sign-up
More from Courier
Develop a Motivational QOTD with Courier and GPT2
Courier and OpenGPT2 in action: build a service that sends friends and family an AI generated motivational quote of the day.
Prakhar Srivastav
February 09, 2023

Decode: Live Workshops to Build Exceptional Notification Experiences
Live coding workshops to build exceptional notification experiences for developers.
Shreya Gupta
February 02, 2023
Free Tools
Comparison Guides
Build your first notification in minutes
Send up to 10,000 notifications every month, for free.
Get started for free
Build your first notification in minutes
Send up to 10,000 notifications every month, for free.
Get started for free
© 2024 Courier. All rights reserved.