Hacking PostgreSQL Internals to Deliver Push Notifications
Tejas Kumthekar
January 20, 2022

PostgreSQL announced their latest version (PostgreSQL 14) on September 30th, which includes a bunch of features like pipeline API, gathering statistics on replication slots, query parallelism improvements and so on. While the origin of PostgreSQL can be traced back to 1986, it has been in active development for the past 30 years. Tons of companies, agnostic of the type and size, have trusted Postgres over the years and their tagline “The world's most advanced open source relational database” is hardly an overstatement.
In a typical, non-trivial system, there is more than one database server, and the data is often copied across multiple servers. A fairly common notion in a distributed system, this copying of data across multiple server nodes is known as replication. Replication processes are often abstracted from the consumers of the database, so most of the application layers are transparent to which node serves the data and if you’re an app developer like me, we expect things to “just work”. However, what goes behind the scenes of some of the most sophisticated databases of the world is often a fascinating reading and learning experience.
In this post, we will start diving into the internals of Postgres to understand how replication works and data integrity is ensured using WAL (Write-Ahead Logging). We will then steer towards interesting concepts like logical decoding and output plugins. Finally, we will start hacking some code to write our own plugin that can send push notifications! I know this sounds a bit contrarian to the common approach of sending notifications from application servers, but hey what's the fun in doing common boring things! Let's dive right in :)
Replication at a high level is a process of transferring data from a primary server to a replica server. In Postgres lingo, servers can either be primary or stand-by. Primary servers are the ones that send data, while standbys are the receivers of replicated data. In certain settings, standbys can also act as senders. Replica or standby servers can take over if the primary fails which is the crux of how database systems manage fault tolerance.

WAL (Write-Ahead Logging) is the standard method to ensure data integrity in Postgres. Systems are bound to fail and database servers are not excused from that. At the application layer, it's comparatively easier to retry and manage failures without typically resulting in data loss, however, when we go deep in the stack, especially at the data layer, persistence is doubtlessly super critical. When consumers make a write operation to the database, before the database is acted-upon, the changes are written to the server’s file system. This by design ensures data persistence and recovery in the cases of operating system crashes or hardware failures. Consumers are (obviously) abstracted from these internal mechanisms and applications connected to the Database expect things to work out of the box.
The log entry we talked about above is known as the Write-Ahead Log record while the process is called Write-Ahead Logging. Each record has a Sequence number which is used for checkpointing periodically after logs are synchronized to the database. In cases of system crashes, this checkpoint is used to re-read and synchronize. WAL, being a reliable method for synchronizing or recreating the ordered state of the database, is used for replication across multiple servers. WAL can replicate the data using either a File based approach or a Streaming approach where both approaches have their own pros and cons. Streaming replication, although is typically in an asynchronous mode, can be tuned to be synchronous.
 https://hevodata.com/learn/postgres-wal-replication/
https://hevodata.com/learn/postgres-wal-replication/
WAL records being representative of the internal state of the Database system, are not easy to be fed into or understood by an external system/consumer. Logical Decoding to the rescue! “Logical decoding is the process of extracting all persistent changes to a database's tables into a coherent, easy to understand format which can be interpreted without detailed knowledge of the database's internal state.” Using logical decoding, replication solutions and auditing can be achieved much easily.
The following diagram depicts the logical decoding process.
 Source:
Source: In order to enable the logical decoding, you need to make some configuration changes to the Postgres instance -
Copied!
wal_level = logical # default value is `replica`max_replication_slots = 1 # good enough for a sample projectmax_wal_senders = 1 # default is 10
Ref: https://www.postgresql.org/docs/current/runtime-config-replication.html and https://www.postgresql.org/docs/current/runtime-config-wal.html for details on tuning the configuration
Once we have the configuration up and running, record changes are passed to the Output Plugin which does the key step of transformation from the WAL format to the format specified in the plugin (eg. JSON). These changes are made available on the replication slot(s) and consumer applications can receive the stream of updates as and when those occur.
Some output plugins and consumer apps out there -
wal2json Output Plugin that converts WAL output to JSON objects [Open Source] pg_recvlogical Postgres app that can consume update stream [Out-of-the-box with Postgres] decoderbufs Output Plugin that delivers data as protobuf [Open Source, Used in Debezium]
We can write a consumer from scratch or use battle-tested tools built to achieve this at scale. Debezium is one of the most widely used solutions out there. Netflix open sourced their in-house tool for CDC called DBLog - https://netflixtechblog.com/dblog-a-generic-change-data-capture-framework-69351fb9099b is a fantastic read on it.
What are we building? Lets keep this simple - whenever a new user entry is made to Postgres table, we will consume replication logs and send a welcome email to the user.
Let’s hack some code! We will be using a Go package https://github.com/jackc/pglogrepl which is a Postgres logical replication library.
Step 1: Follow Logical replication instructions
https://github.com/jackc/pglogrepl README has step by step instructions to configure logical replication in your local Postgres Instance.
Step 2: Try out the demo in the repo
Give https://github.com/jackc/pglogrepl/tree/master/example/pglogrepl_demo a try - it demos how the library works under the hood
Step 3: Update the demo code to log new email inserts
To keep it simple for this blog post, let's add some code that prints out specific email which was inserted on the new row.
A. Look for inserts and print the WAL data
Copied!
if logicalMsg.Type() == 'I' {// `I` stands for Insertlog.Println(string(xld.WALData))// this logs the complete entry// however it would require a little more cleanup}
For example, a new entry with ID 5 and email tejas@courier.com shows up as I@Nt5ttejas@courier.com
B. Clean up the internal WAL representation and derive email
Copied!
// find the second columnwalData := xld.WALData[5:]pos := bytes.Index(walData, []byte("t"))email := walData[pos+1:]pos = bytes.Index(email, []byte("t"))email = email[pos+1:]emailStr := string(email)
C. Send a welcome email to the user
We will be creating a new template by configuring an email integration supported by Courier.
Copied!
messageID, err := client.Send(context.Background(), "VDPE8SWN1K4BWMP8RJ101YRZTF3J", "user-id",courier.SendBody{Profile: profile{Email: emailStr,},Data: data{Foo: "bar",},})if err != nil {log.Fatalln(err)}log.Println(messageID)
Find the modified code at https://github.com/tk26/pglogrepl Here’s a quick loom video of how things work.
Now that we have configured Postgres to send emails by listening to replication logs, changing it to send a push notification would be as simple as changing a configuration in the Courier Studio.
Thanks for reading! Reach out to us @trycourier if you have any questions or comments or you know, just say Hi!
Similar resources

Inbox SDKs for Vue and Angular: a native in-app notification center
Courier now ships first-class inbox SDKs for Angular and Vue. Drop in a real-time notification center, toasts, and a preferences center with native components, an injectable service, and a composable, all backed by the same in-app inbox that already powers React and JavaScript apps.
By Mike Miller
June 19, 2026

Human-in-the-loop for AI payment agents: building approval notifications that work
AI agents need human approval before taking consequential actions: financial commitments, irreversible changes, decisions that affect other people. This post covers how to design those checkpoints and build the notification infrastructure: multi-channel delivery, live context, escalation, and a back-and-forth question loop between reviewers and the agent.
By Eric Lee
May 26, 2026
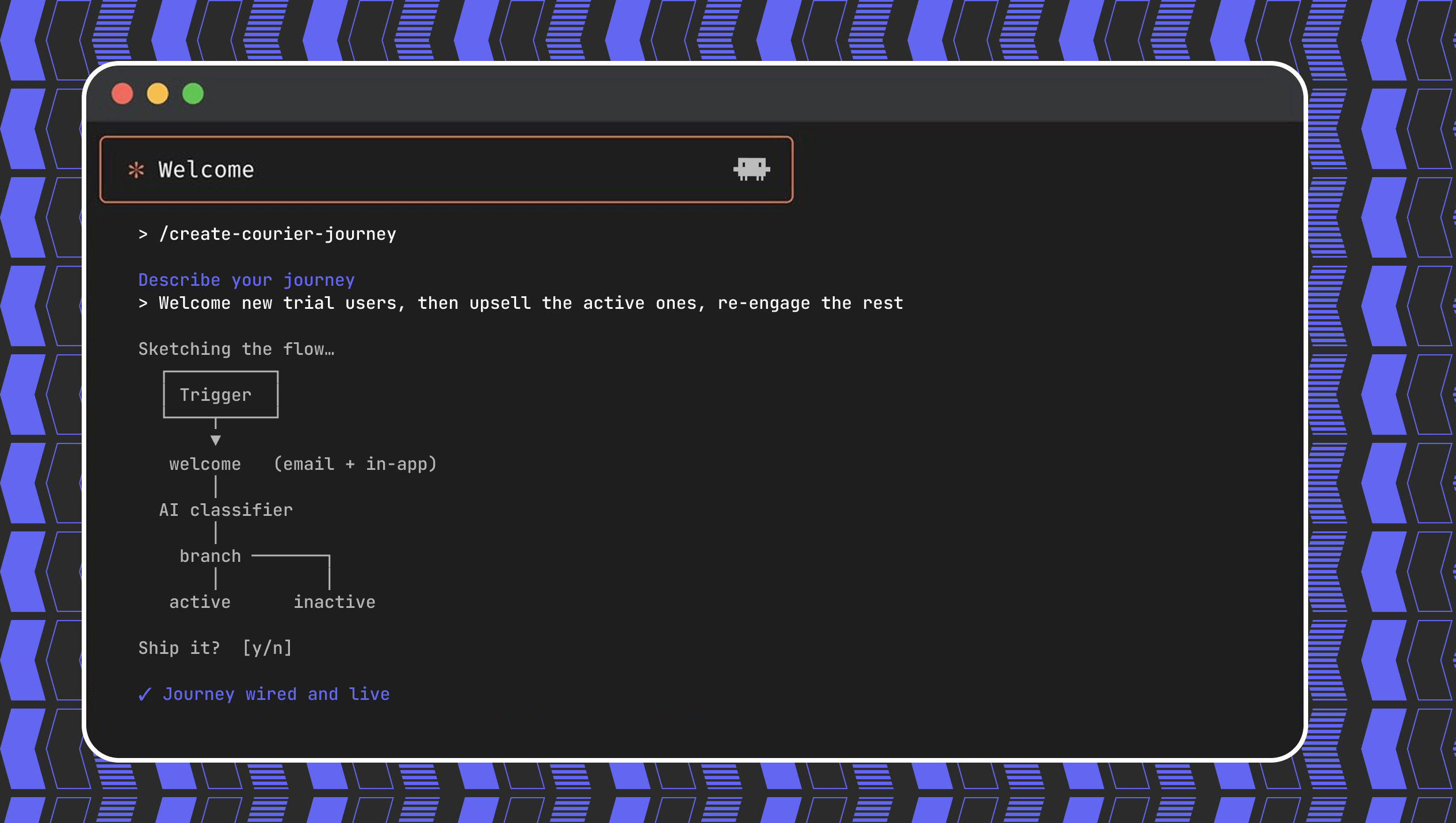
Create a customer journey from AI coding agent
Use Courier's Journey API to create multistep customer engagement workflows from your coding agent of choice. Describe the kind of journey you'd like to create, answer a few questions, and publish to the platform.
By Kyle Seyler
May 20, 2026
© 2026 Courier. All rights reserved.